




Excel SEO: функции полезные при обработке текстов и таблиц
Как-то не совсем удобно начинать с очевидных фактов, но хочется, чтобы история была максимально правдивой. Придя в SEO-копирайтинг, специалист по написанию статей учится овладевать текстовыми сервисами в меру своей загруженности и обязанностей. Один из них – Excel. В документах этого приложения посылаются технические задания авторам для написания статей. Особых навыков иметь не надо. Все уже сделано оптимизаторами, маркетологами, прочими специалистами. Но вот однажды, пришло задание: написать статью о связи Excel с SEO. Самое лучшее, что приходит в голову, описать функционал, используемый нашими сотрудниками в каждодневной работе. Посмотрим, какие инструменты посоветуют они для упрощения профессиональных обязанностей.



Функции на службе SEO для каждого рабочего дня
Необходимость первой предложенной F(x) понятна даже простому копирайтеру. Различные сервисы, гостевые сайты, прочие ресурсы выставляют ограничения по допустимой длине символов в URLUniform Resource Locator или сокращенно URL - это стандартизированный, принятый повсеместно способ прописки адреса веб-сайта в глобальной сети. В дословном переводе термин…Перейти к словарю терминов странице, ее TitleTitle (в переводе с английского языка "название, заглавие", жаргонно - титул или тайтл) - основной заголовок, которые не демонстрируется на веб-странице, а…Перейти к словарю терминов , descriptions. Проверять каждую статью отдельно, затратно по времени. Проще воспользоваться функцией =ДЛСТР (), называемой в английской версии LEN.
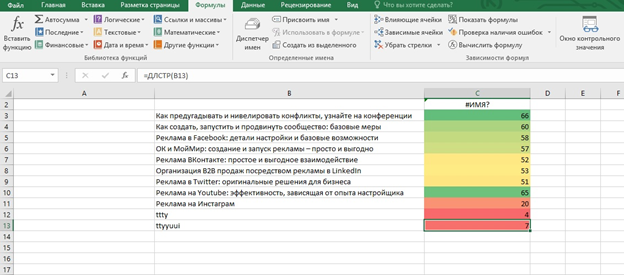
Допустим нам надо, чтобы длина названия по количеству символов находилась в диапазоне 40-70. Тогда можно воспользоваться дополнительной формулой и задать разный цвет для каждой длины строки. Тогда практически сразу станут видны тексты, в которых нарушены минимальные требования.
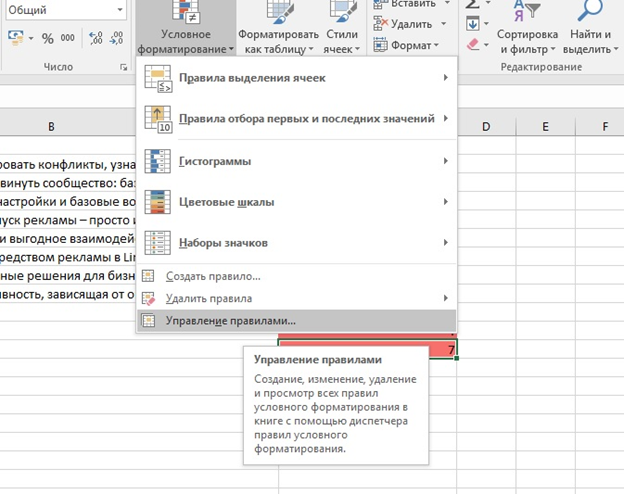
Правило можно создать или изменить.

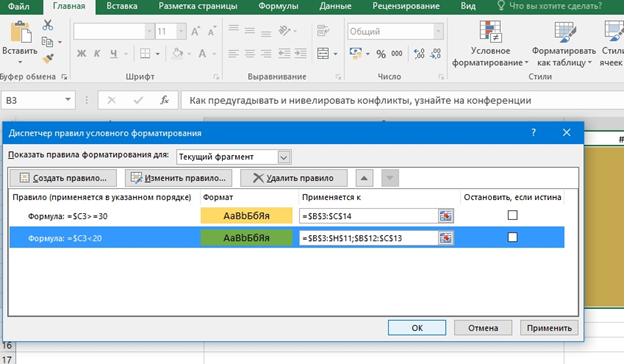
Такой небольшой экспромт отлично демонстрирует, как быстро настроить работу в Exel к нуждам SEO. Таким образом, проверяют десятки текстовых параметров, которые необходимо добавлять в особые зоны на странице. Эта же функция полезна при заполнении карточек товаров, когда короткие описания до 255 символов добавляются рядом с техническими данными изделий.
Следующую важную функцию не показать также наглядно. Это F(x): СЖПРОБЕЛЫ или TRIM, убирает из текстов лишние пробелы. На практике так же полезна при заполнении карточек товаров через форму Exel. Также в случаях, когда происходят частые копирования и в разных фрагментах текстах появляются лишние пробелы.
Description часто требуется вставлять в форму сниппета, используя курсив. Сделать это быстро и массово поможет ПРОПИСН (UPPER), СТРОЧН (LOWER).
ПРОПНАЧ (PROPER) – функция аналогичная той, что есть в Word: «Начинать с прописных». Она нужна, когда после множественных проверок, текстContent - контент или содержимое - собирательный термин, под который подходит все данные на информационных ресурсах - тексты, графика, видео. Разновидности…Перейти к словарю терминов возвращается к владельцу только прописными или заглавными буквами. Тогда, например, КОМПАНИЯ+НАЗВАНИЕ города долго приходится переписывать. ПРОПНАЧ (PROPER) избавляет от необходимо заново набирать слова полностью.
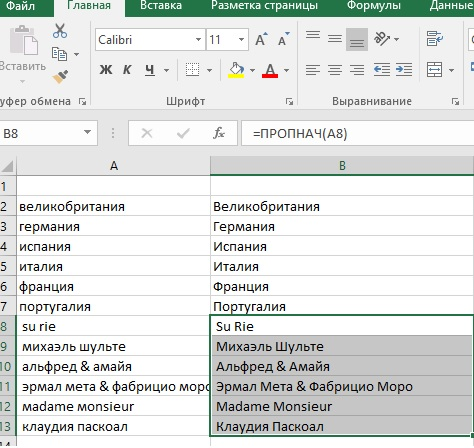
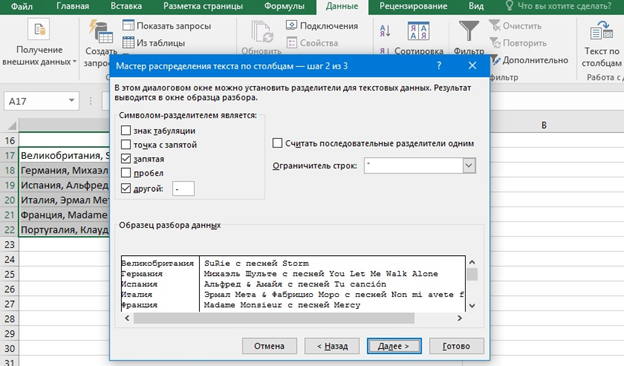
Здесь попутно могут понадобиться другие функции: разделения текста по столбцам и обратного «склеивания» текста.
Первое делают с помощью Данные > Текст по столбцам.
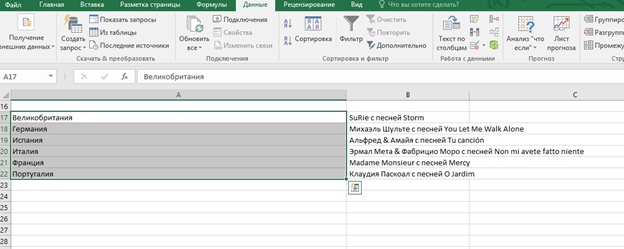
Изначально имели такой текст:
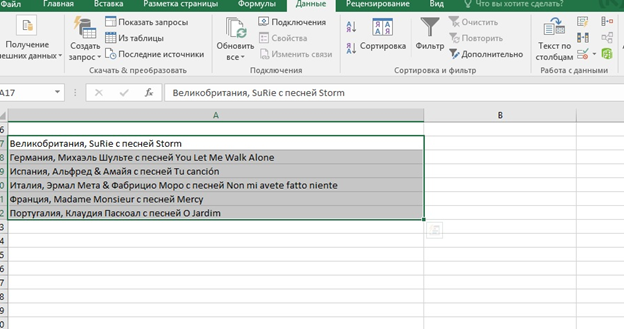
Объединить текст можно при помощи СЦЕПИТЬ (текст1;текст2;текст3…) (англ. CONCATENATE)
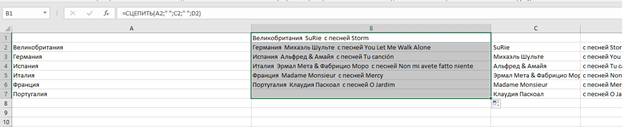
По честному признанию SEO-специалистов, функция =Сцепить используется ними наиболее часто. Здесь можно объединять следующее:
- фрагменты, размещенные в столбцы, разделяя их знаками препинания или просто пробелами (иначе текст «слипнется»);
- фразы+текст в столбцах;
- цифры.
В самой формуле нет ничего сложного. Но надо правильно расставлять знаки препинания, предусмотренные Exel. Как например, текст даже, если это просто пробел «обрамляют» кавычками. Каждый завершенный фрагмент отделяют точкой запятой. Таким образом можно сделать заметку из 255 объектов (каждый имеет собственное число слов или знаков). Общий объем текста не должен превышать 8192 символа (статья примерно 900 слов).
Более практичное применение этой функции. Когда, например, 100 сайтов надо присвоить одинаковый или разные анкоры. Если использовать уже описанный метод, где мы указываем не столбец, а конкретную ячейку, лучше брать абсолютные адреса. Они выглядят так: “]$A$1.
Дополнительно обращаем внимание, что есть необходимость брать название сайта в двойные кавычки. При задании формулы используют цифровое значение это знака препинания: символ(34).

Следующая интересная для специалистов по SEO функция - СЧЁТЕСЛИ (диапазон;критерий) (англ. COUNTIF).
Она используется, когда надо приблизительно понять, каково процентное присутствие в списке анкоров объектов с URL. О чем важно знать при составлении формулы? Поиск идет по точным заданным параметрам. Если задано, есть ли в формуле «domen.com», то ответ будет определен по наличию именно такого URL. То есть, стоящие рядом другие слова или знаки препинания воспринимаются единым тестом вместе с «domen.com».
Исправляют ситуацию добавлением в формулу звездочек, ее фрагмент будет выглядеть так: «*domen.com*». Напоследок, приходится учитывать пустые ячейки также. Иначе они также войдут в расчет и вместо 40% можно получить всего 4. Решают эту проблему улучшением формулы до вида:
+считатьпустоты(адрес стартовой ячейки:адрес конечной ячейки)
Если на базе примера с функцией сцепления в списке произвести небольшие изменения, то в итоге получается результат, показанный на скриншоте.

Иногда в работе SEO-специалиста требуется знать номер позиции, где заканчивается или начинается интересующий текст. Это необходимо для задания других формул, выполняющих добавление или отсечение лишнего текста. Все вместе используется в случаях, когда требуется привести таблицы к стандартному виду.
Сначала применяют =Поиск или =Найти. Первая работа без учета регистра букв, вторая восприимчива к написанию с прописной или строчной.
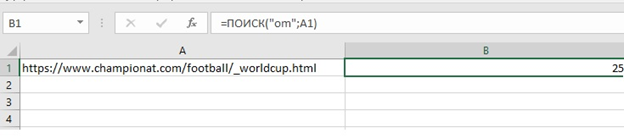
Мы не имеем отношения к конкретному сайту, но как футбольные болельщики не можем пропустить грандиозное событие. Теперь, если мы хотим, чтобы результат отображался только написанием главной страницы сайта, используем функцию ЛЕВСИМВ. В конкретном случае, мы хотим оставить в таблице только 25 символов. Отметим также, что список URL, предположительно размещенный ниже, для каждого другого случая показал бы другое число.
Применим ЛЕВСИМ и посмотрим, что получилось:

Важно, что эти действия вполне применимы для списков на несколько сотен строк.
Аналогично работает функция ПРАВСИМВ.
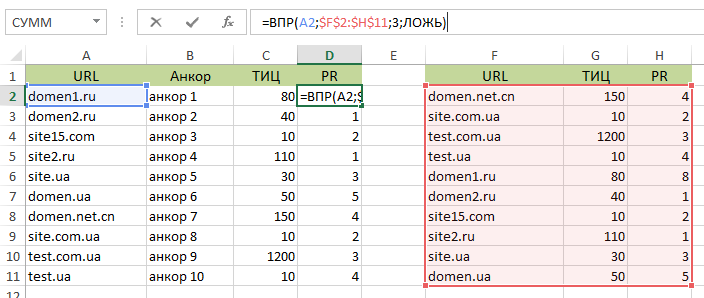
Перейдем к ВПР или VLOOKUP. Когда вам необходимо согласовать и объединить несколько таблиц, учитывая содержимое ячеек, удобно использовать эту функцию.
Предположим имеется придуманный список ссылающихся на наш портал анкоров. В нем также могут быть домены, ИКС, DR, относящиеся к донорским ресурсам.
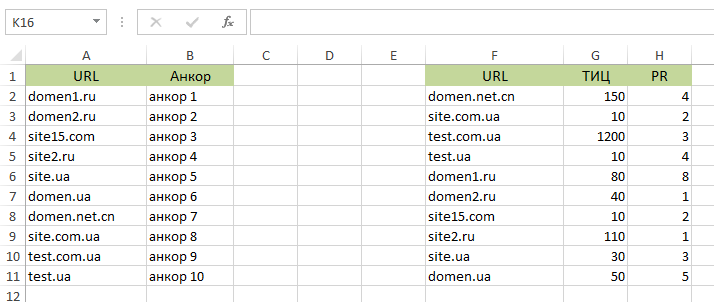
Эти две таблицы отличаются последовательностью, в которой упоминаются сайты. Перенести данные из 2 в 1 достаточно сложно. Практически имеется такой выбор:
1. Сделать все руками.
2. Использовать функцию ВПР.
Испытаем второй вариант:

После применения получаем следующее:
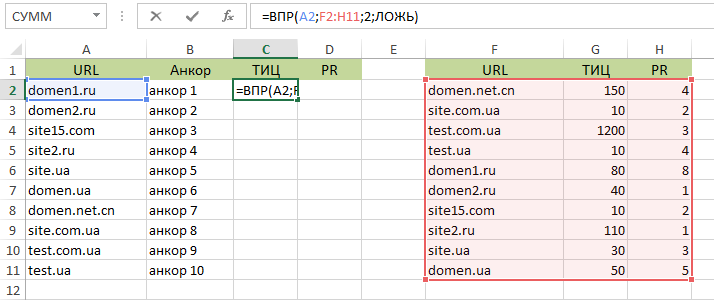
Распишем полученный результат:
А2 – это то, к чему мы ищем подходящие данные в таблице.
F2:H11 – наша область поиска.
«2» - номер столбца, данные из которого надо переместить в таблицу 1. Для конкретного примера, идет поиск ИКС и соответствующих доменов.
ЛОЖЬ или ИСТИНА зависит от того, насколько точные нужны результаты. В конкретном случае, выбираем ЛОЖЬ и ведем поиск точного соответствия фраз слева и справа.
Немного запутанней с выбором «Истина». Если работа идет с цифрами, то в правой колонке функция находит ближайшее в сторону убывания значение (при условии, что отсутствует точное). Еще одна примечательная особенность этого оператора: что содержимое ячейки, встреченное дважды, будет учитываться однократно по первому в списке числу. Чтобы результат получался корректным, стоит установить сортировку в порядке возрастания.
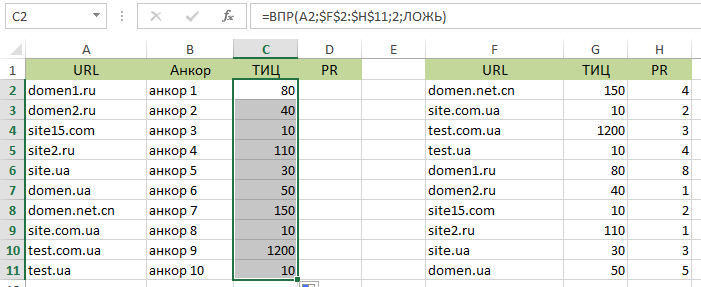
Когда действия завершены, аналогично заполняют третий справа столбец. Дополнительно можно вместо относительныхОтносительная ссылка - линк, который указывает не полный путь к документу/файлу. При этом путь данной ссылки можно высчитать лишь относительно чего-либо -…Перейти к словарю терминов , использовать абсолютные адреса, записываемые в окружении специальных символов, например: A2;$F$2:$H$11. Тогда значения будут присваиваться нужным ячейкам. Это необходимо, поскольку при обычном растягивании все строки будут заполняться, как первая.
Очистка текста от дублей
Закончили. Теперь особенно полезное для SEO-специалиста. Это встроенные функции. Их применяют для очистки текстов от дубля. Используют Данные > Удаление дубликатов или в оригинальной версии: Data > Remove Duplicates.
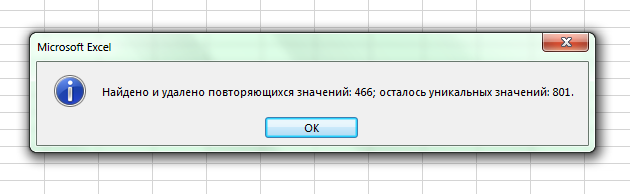
Предположим имеется перечень элементов из 1200+ наименований сайтов. Найти дубли в таком тексте довольно затруднительно даже вручную. Как вариант, можно сделать сортировку по алфавиту и далее уже удалять повторяющиеся названия. Дополнительно к этому подключают специализированный софт для работы с ключевыми словами. Но это уже не к копирайтеру, а специалисту более высокого класса. К нему же придется обратиться, если в списке около или больше миллиона значений. Но для выбранного нами примера подойдет Exel и его функции.
Предположим изначально имеется 1266 доменов + topodin.com, как на картинке:

Выделяем полностью весь список, любым доступным способом. В строке управления находим «Данные», там «Удалить дубликаты».
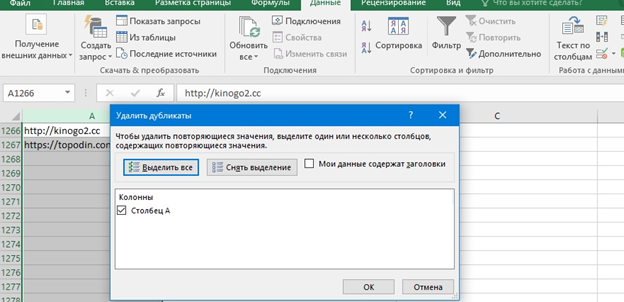
Нажимаем «ОК» и ждем результатов.
Аналогичное действие выполняется при помощи сервиса Google Docs Spreadsheet. Возьмем еще один список, где некоторые из доменов повторяются. Для удаления в этом сервисе применяют функцию = UNIQUE (массив).
Для первого раза неплохой поход в мир Exel&SEO. ЗнаниеНабор формул, в соответствии с которыми осуществляется формирование выдачи и ранжирование веб-страниц. Основная задача алгоритма ПС - продемонстрироватьПерейти к словарю терминов получено, осталось обрести навыки, как работа с тысячами параметров станет гораздо легче.








