




Поисковая система Google: попытка регистрации стандартов
Возможность закрывать часть страниц сайта от индексирования посредством директивы noindex или disallow в robot.txt использовалась оптимизаторами для эффективного продвижения. Поэтому беседа, начатая на страницах Twitter и поддержанная официальными представителями Гугл, стала объектом внимания № 1 среди SEO-специалистов.



Правила из этичности или удобства: стремление к стандартизации
Однако в процессе изучения темы выяснилось, что вопрос не ограничивается лишь одним отказом воспринимать директиву noindexNoindex - популярный в Рунете HTML-тег, введенный компанией Яндекс. Используется веб-мастерами для запрета индексации определенного фрагмента веб-страницы. Учет…Перейти к словарю терминов . Компания решила полностью пересмотреть отношения к стандартам интернета. До сих пор сканирование сайтов происходило по правилам, прописанным внутри файла robots.txtRobots.txt (в русскоязычной транслитерации - "роботс") - файл, позволяющий регулировать индексацию веб-ресурса ведущими поисковиками. Этот текстовый документ…Перейти к словарю терминов . Ситуация сохранится до сентября 2019 года. Регламент формировался на основании того, что диктует протоколHTTPS - современное расширение протокола передачи данных HTTP, отличающееся поддержкой шифрования. Для дополнительной защиты тут задействованы протоколы SSL и/или TLS,…Перейти к словарю терминов Robots Exclusion Protocol (REP). Однако этот документ нигде на официальном уровне не числится. Поэтому часто оптимизаторы подстраивались к вероятным действиям поисковых систем при ранжировании проектов. Теперь же Google заговорил о возможности утвердить протокол в специально созданном для таких целей органе сети: Internet Engineering Task Force (Инженерный совет интернета).
Разработчики Гугл подчеркивают:
- До настоящего момента в сети нет четкого протокола действий, утвержденных официально.
- Правила обработки трактуются по-разному, более того необязательны к исполнению.
- Возникла потребность задокументировать REP-протокол, что станет удобным и полезным участникам сетевого общения.
Файл robots.txt: взаимодействиеUsability (в переводе с английского "удобство использования") - степень удобства пользователя в процессе взаимодействия с интерфейсом веб-ресурса, а также набор…Перейти к словарю терминов с поисковыми краулерами
Для появления сайта в интернете, кроме покупки хостинга и домена, необходимо выполнить и другие условия для его открытия. Создать изначально каркас, где прописаны мельчайшие детали его реализации в сети. Вместе с правилами о создании конкретных элементов, их функционала и размещением на экране прописывается регламент для поисковых ботов. Такие директивы, как noindex или disallow предназначаются краулерам поисковых систем, исходя из конкретики ситуации (только для Яндекс или Гугл, Yandex, Bing, прочих). Вместе с тем оптимизаторы могут ограничивать доступ к данным проектам любым ботам, запущенным для сканирования страниц. Задание ограничений необходимо, прежде всего, для снижения нагрузки на веб ресурс, что особенно актуально для проектов с высоким трафиком. Попутно с этим добиваются уменьшения расходов на пропускную поддержку канала.
Однако отсутствие официальных стандартов относительно протокола REP вызывало ряд неудобств. Некоторые из них затрагивали интересы Гугл.
Что ожидается от стандартизации протокола и его регистрации в ITTF?
Представители поисковой системы Google воздерживаются от развернутых комментариев. Однако из информации поданной на последней конференции, в мае 2019, а также публикаций в социальных сетей, напрашивается отчетливое видение последствий от документации протокола. Положительное решение вопроса должно помочь достичь таких целей:
- Модернизация функциональной базы за счет задания точных правил для краулеров, обязательных к исполнению в конкретных объемах.
- Уход от двояких формулировок и неоднозначной трактовки использования тех или иных указаний.
- Повышение эффективности работоспособности аналитических систем, предсказуемости прочтения и выполнения краулерами файла robots.txt.
К каким конкретным изменениям готовиться?
Обновления коснутся самых разных сфер деятельности в интернете. Но главное– появится зарегистрированный протокол. Поэтому изменения скорее коснуться технической реализации проектов, чем маркетинговой или просто пользовательской сторон.
Что станет можно или должно исполнять краулерам:
- Разрешается применять директивы для любых типов URLUniform Resource Locator или сокращенно URL - это стандартизированный, принятый повсеместно способ прописки адреса веб-сайта в глобальной сети. В дословном переводе термин…Перейти к словарю терминов . Кроме, HTTP/HTTPS, допускается установка правил для форматов FTPFile Transfer Protocol - сокращенно FTP (в переводе с английского - протокол передачи файлов) - интернет-протокол, позволяющий осуществлять передачу данных в сети. Его…Перейти к словарю терминов или CoAP.
- Фиксируется минимальный объем сканирования документа – первые 512 КБ.
- Краулеры не должны исследовать запись полностью, если объект слишком велик.
- Поисковый бот не обязан сканировать сайт при низкой стабильности соединения.
- Директивы обязательно кэшируются. Цель этого изменения – уменьшить число обращений к серверу.
- Сохранение остается актуальным не более чем на сутки. В Гугл посчитали, что этого времени достаточно оптимизаторам для своевременного обновления файла.
- Заголовок Cache-Control позволит самостоятельно задавать правила кэширования.
- Отсутствие доступа к файлу не отменяет действия директив, описанные правила сохраняют силу долгое время после утраты возможности сканировать документ.
Кроме перечисленных изменений в регламенте работы краулеров по ограничениям документа, рассматриваются и директивы, которые непосредственно формируют файл robots.txt.
Окончательный текст документа о стандартизации протокола еще не зарегистрирован и не утвержден в ITTF. Но уже сейчас есть данные, что Google не будет поддерживать правила, которые не попадут в официальную форму проекта.
Поскольку предварительная форма документа создана разработчиками указанной поисковой системы, стоит прислушаться к заявлениям, говорящим об отказе следовать правилу noindex. Анонсировано отключение поддержки на 1 сентября 2019 года.
Дополнительно ко всему, поисковая система Google открыла доступ к алгоритму анализа файла robots.txt (код парсера для конкретного объекта).


Изучение документа дает возможность понимать, приоритетные решения поискового краулера в различных ситуациях. Интересный факт, директива disallow не теряет силы даже, если ключевая фраза написана с опечаткой. Так, что консалтинговый компаниям придется пересмотреть некоторые пункты в аудитах сайтов. Например, упоминание ошибок, аналогичных приведенным – бессмысленное занятие.
Как надо привыкать делать?
До сих пор директива noindex считалась лучшим по эффективности методом, чтобы закрыть страницы от сканирования. Реализация устранения из индекса сервисов поиска станет возможной посредством задания noindex в следующих зонах:
- метаМетатег или Meta-tag - html-тег, применяемый для передачи важнейших структурированных данных о веб-страничке. Они указываются преимущественно в верхней части файла.…Перейти к словарю терминов -тег robots;
- HTTP заголовки.
Во втором случае необходимо прописывать заголовок X-Robots-Tag. Для любой страницы, закрываемой от индексации, правильный синтаксис выглядит так:
X-Robots-Tag: noindex
В ситуации с ограниченным доступом к ресурсам сайта, например, исключительно к его шаблонам, рекомендуется прописывать мета-тег, который стандартно выглядит так:
<meta name="googlebot" contentContent - контент или содержимое - собирательный термин, под который подходит все данные на информационных ресурсах - тексты, графика, видео. Разновидности…Перейти к словарю терминов ="noindex">
Что собственно означает указание для краулера Гугл – не проводить индексацию страницы.
Как и ранее ограничить доступ к сканированию документов от остальных ботов, надо использовать robots вместо имени краулера системы Google. Читатели могут поупражняться и в предшествующей командной строке выполнить самостоятельную замену имен.
Альтернативой noindex служит манипуляция с кодом ответа. Известные всем «Ошибка 404Ошибка 404 или Not Found означает, что запрашиваемый ресурс может быть доступен в будущем, что не гарантирует прежнее содержание, а на данный момент доступа к нему нет.…Перейти к словарю терминов » или «Ошибка 410» также ведут к выводу страниц из кода поисковых систем.
Еще один актуальный вопрос для оптимизаторов, как регулировать временные рамки кэширования? Чтобы указать срок, на протяжении которого скачанные данные доступны к повторному использованию, теперь используют Cache-Control. Прописывается так:
Cache-Control: max-age=[время в секундах]
За начало периода принимается момент, когда совершен запросЗапрос — слово или символ, вводимое в строке выдачи.Используется расширенный поиск:1) Оператор «+» (или кавычки) перед требуемым словом ищет запросы с…Перейти к словарю терминов . При этом max-age, указанный в секундах, сообщает длительность периода, когда доступно скачивание и использование ответа. Результирующая схема обработки объекта имеет вид:
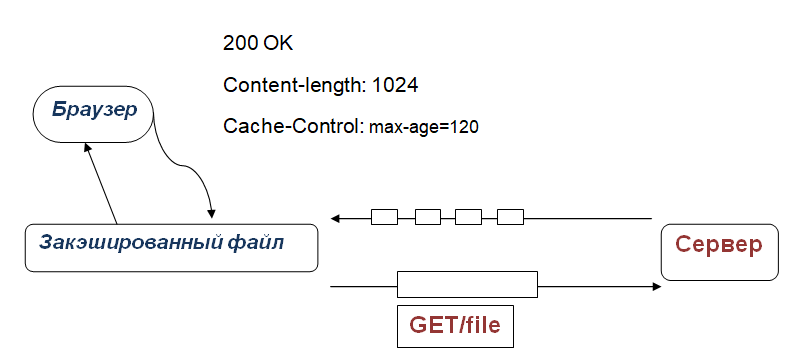
Нюансы правильного конфигурирования robots.txt
Корректность написания директив в тексте файла смотрят посредством инструментов Google. Один из них - Google Robots.txt Tester. Сервис работает бесплатно, проверяет синтаксис, предупреждает об ошибках иного рода, если таковые имеются. Оптимизаторам следует проявлять внимательность, поскольку ссылки из robots.txt восприимчивы к стилю написания (прописные или строчные буквы). Например, ниже приведенные ссылки считаются абсолютно разными:
topodin.com/lt/job_topodin.php
topodin.com/lt/JOB_TOPODIN.PHP
Надо учитывать, что тестировщик от Гугл не распознает подобные ошибки.
Как относятся к noindex прочие поисковики сети?
Проблема, которую «вскрыл» Гугл, заключалась в отсутствии каких-либо правил относительно прочтения robots.txt, в том числе, директивы noindex. Для оптимизаторов важно и то, как воспринимают правила аналитические системы, прочие сервисы интернета. Например, веб-архиватор Wayback Machine в разные периоды менял правила сканирования страниц. Среди известных поисковых систем, как минимум, две не поддерживают директиву noindex именно в robots.txt: Yandex и Bing. Яндекс предлагает прописывать правило в мета теге robots или X-Robots-Tag.
Файлы стилей и скрипты: как рекомендуется поступать с ними?
Сервис Гугл недавно обновил алгоритмы сканирования краулера Googlebot. Владельцы сайтов, использующие оптимизацию визуализации, получают массу преимуществ. Ранее в Google не учитывались многие факторы, присутствующие на страницах. Например, наличие «ленивой» загрузки, упрощение понимания скриптов. Теперь, когда обновление системы внедрено и уже используется, у владельцев есть стимул заботиться о более качественной и скоростной «отрисовке» страниц. Сайты, где доступ к стилям и скриптам окажется закрытым, не смогут в полной мере ощутить выгодные для них нововведений. Поисковая система не сможет корректно ранжировать проект из обязательной последовательности действий: сначала визуализация проекта в глазах краулера, затем присвоение странице места в выдаче. Если в документе имеются улучшения, которые закрыты для сканирования, даже очевидные преимущества останутся незамеченными.
Взаимодействие ботов с документацией страниц до ранжированияНабор формул, в соответствии с которыми осуществляется формирование выдачи и ранжирование веб-страниц. Основная задача алгоритма ПС - продемонстрироватьПерейти к словарю терминов проходит по следующей схеме:
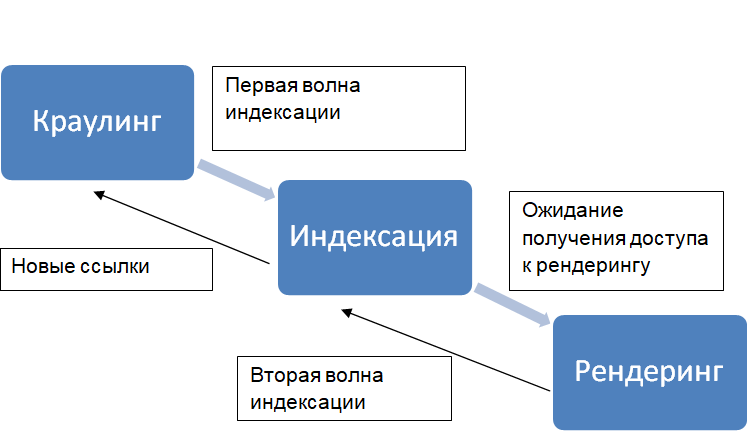
Краулинговый бюджет: изменится ли что-то в этом направлении?
Данная тема обсуждается в свете всех последних изменений в работе алгоритмов поисковой системы Гугл. Ранее выяснилось, как влияют изменения в принципах сканирования страниц. Эксперты пришли к выводу, что новое видение проектов, а также отношение к директивам noindex не оказывают влияния на краулинговый бюджет.
Тогда, как грамотное использование Disallow в robots.txt, позволяет сокращать расходы. Экономия достигается за счет сокращения числа сканируемых страниц.
В общих случаях, следует учитывать, что затраты по краулингу обусловлены только парой факторов:
- Авторитетность домена.
- Допустимая нагрузка на сервер.
Репутация определяется качеством и объемом ссылочного профиля. Для сокращения краулингового бюджета потребуется постоянный мониторинг внешней ссылочной массы проекта. Сделать это можно посредством различных аналитических приложений.
Особенности работы с поддоменами
Место размещения robots.txt влияет на область, где действуют правила, установленные в нем. Если документ загружен на site.com, то директивы действительны лишь для этого домена. Когда требуется применение правил на www.site.com, файл необходимо размещать на этом же хосте. Проще говоря, для использования директив на поддоменах robots.txt должен загружаться с поддоменов.
Подведем итоги
Стандарты, устанавливаемые в robots.txt, применялись для работы в глобальной сети более 25 лет. До сих пор это был документ, подчиняющийся каким-то общим соображениям. Вопросы исполнения директив поднимались исполнителями (владельцами сайтов), но дискуссии вокруг темы велись исключительно ознакомительные и образовательные. Если в итоге для документации robots.txt будет принят единый стандарт, появится определенность в применении устанавливаемых правил и их трактовке.
Впервые регламентированы минимальные размеры файла, достаточные для проведения индексации страниц.
Если сканируемый документ оказывается больше, то работать будут только первые 512 кбайт.
Ожидается, что протокол REP станет стандартом для всей сети. Проект документа опубликован на веб ресурсе ietf.org с пометкой «черновик».
Гугл отказывается от поддержки директивы noindex, прописанной в robots.txt.
Чтобы страницы не попадали в индекс системы надо использовать специальный заголовок или мета-тег. Проекты, которые необходимо удерживать «скрытыми» до момента запуска, закрываются на уровне серверов.
Сайты на HTTPS должны предоставлять доступ к robots.txt по соответствующему протоколу.

Нужна помощь?
Предлагаю обсудить план продвижения по телефону. Оставьте ваши контакты ниже и мы вам перезвоним!
Ксения Смирнова (SEO-аналитик)
В реальности, анонсированные модификации ведут к необходимости выполнить ряд мероприятий:
- Очистить robots.txt от noindex.
- Добавить к заголовку X-Robots-Tag noindex.
- Альтернативно предшествующему пункту, создать мета-тег content=«noindex».
- Сократить robots.txt до объемов, не превышающих значение 512КБ, поможет использование масок.
- Разрешить краулерам индексировать CSS и JavaScript форматы.
- Применять 404 или 410 код ответа, когда страница подлежит удалению из индекса.
- Задавать длительность кэширования посредством Cache-Control.
Наши специалисты готовы к грядущим переменам. Если вы столкнулись с трудностями при оформлении или размещении файла robots.txt, обращайтесь к менеджерам Топодин. Вам обязательно помогут.







