




Сервис Wayback Machine: архиватор или маркетинговый генератор
Копирайтерам часто приходится обобщать и упрощать некоторые процессы поискового продвижения. Для клиентов не столь важно знать, какие именно сервисы и службы интернета используются с целью повышения эффективности сайтов. Но вопросы появляются и среди наших читателей есть пользователи, ожидающие ответов.



Какую именно информацию добывают посредством Web Archive?
Изначально ставилась цель рассказать об одном сервисе сети, хранящем данные об истории создания и развития проектов. Но мы отталкивались от потребности клиентов заказывать предварительный аудит сайта. Однако в процессе написания всплыли менее очевидные направления, где исследование интернет-проектов посредством поднятия их истории также полезно. Например, анализ конкурентов. Причем сканирование сайтов выглядит весьма многообещающим, поскольку львиная доля информации предоставляется в свободной форме: без регистрации и бесплатно. Среди доступных данных истории интернет ресурсов, их исторические копии. Называются такие сервисы - Web Archive или веб архивы, если говорить по-русски.
К списку исторических информационных данных относят следующее:
- тематика сайта или ниша рынка, где он работает;
- первоначальный дизайн, интерфейс и прочее (интересно для покупателейЛид - термин с различными значениями, используется в сфере интернет-маркетинга. Лидом является отдельная категория интернет-аудитории (потенциальные клиенты) и их…Перейти к словарю терминов б/у доменов на продажу или с исследовательскими целями);
- дата регистрации домена, если таковая есть, чистота проекта в глазах поисковых систем, чтобы в дальнейшем избежать санкций «из прошлого»;
- архивы, по которым восстанавливают проект, если отсутствует резервная копия;
- уникальный или авторский контентContent - контент или содержимое - собирательный термин, под который подходит все данные на информационных ресурсах - тексты, графика, видео. Разновидности…Перейти к словарю терминов (цель найти бесплатные статьи);
- удаленный текст из закладок.
Итак, веб архивы полезны нашим клиентам, интересны конкурентам, покупателям дешевых и добротных доменов, прочим категориям специалистов, обычным пользователям.
Как создавалась и что хранит машина времени сайтов?
Идея проекта была реализована Брюстером Кейлом в 1996 году. Сервис Wayback Machine – не единственный рабочий инструмент проекта archive.org, но один из двух наиболее значимых.
Машина Времени сайтов собирает, хранит и предоставляет доступ к копиям интернет проектов от момента создания до минуты востребования, независимо от действительной функциональности конкретных страниц. Проще говоря, данные можно получить даже, когда сайт прекратил свое существование где-то в прошлом.
В 1999 году сервис приступил к сбору файлов любых форматов: аудио, видео, изображения, программное обеспечение. Данные удобно отсортированы и представлены пользователю.
Для любителей статистики приведем данные о количественном содержании материалов разных типов, имеющихся в открытом доступе:
Параметр | Числовое значение на разные моменты времени |
Страниц | 371 биллион зарегистрировано за все время |
Объем хранилища | 25 петабайт на сентябрь 2018 45 петабайт на март 2019 |
Число сканируемых книг (статей) | 1000 ежедневно |
Изображений в онлайн доступе | 3 млн 329 тысяч на текущий момент |
Правообладатели пользуются своим авторским правом. Поэтому не все данные находятся в открытом доступе. Также будет полезно знать, что с октября 2014 по апрель 2016 Роскомнадзор блокировал проект за публикацию террористического ролика. На данный момент сайт разрешен для российских пользователей. Теперь о самом интересном.
Как работать с веб-архивом?
Пользоваться сервисом удобно. Как мы сообщали ранее, львиная доля информации предоставляется бесплатно. Одновременно с этим, остальные данные можно получить, сделав пожертвование: единожды или регулярно раз в месяц. По утверждению разработчиков, плата за подобные услуги – символичная. И есть мнение, что это действительно так.
Интерфейс приложения минималистичен. Есть шапка страницы, которая занимает открытое или закрытое положение. В этой части документа, а также чуть ниже размещается активная строка поиска, куда необходимо ввести URLUniform Resource Locator или сокращенно URL - это стандартизированный, принятый повсеместно способ прописки адреса веб-сайта в глобальной сети. В дословном переводе термин…Перейти к словарю терминов исследуемого сайта или запросы, имеющие отношение к нему. Второй вариант менее удобен, но отлично подойдет, если название сайта просто забыто.
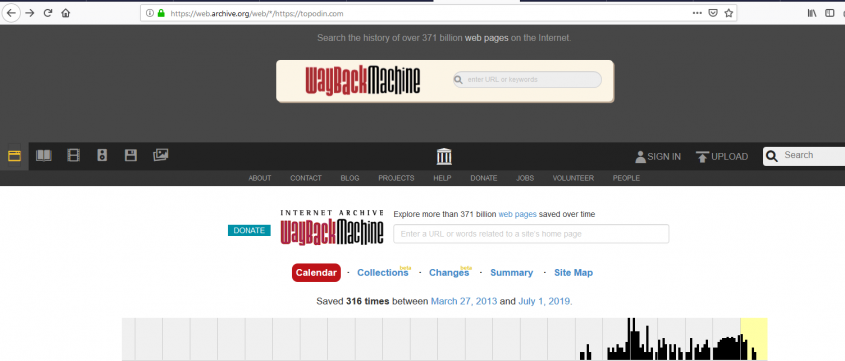
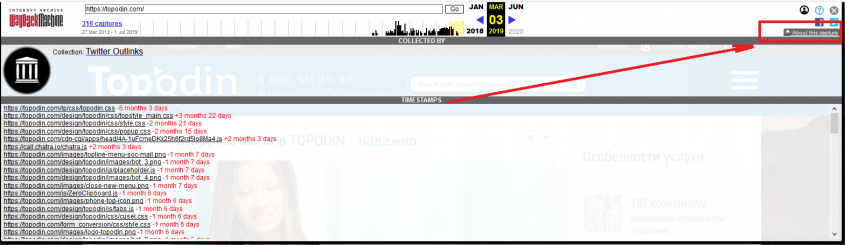
Мы решили поэкспериментировать с проектом Topodin. На скриншоте видно, что по указанному доменному имени первая архивация произошла 27 марта 2013 года. Последние доступные записи, датированы 1 июля 2019. За весь период существования проекта по указанному адресу производилось 316 коренных изменений. Сказать точнее, именно столько архивных копий можно получить из приложения Машина Времени Сайтов.
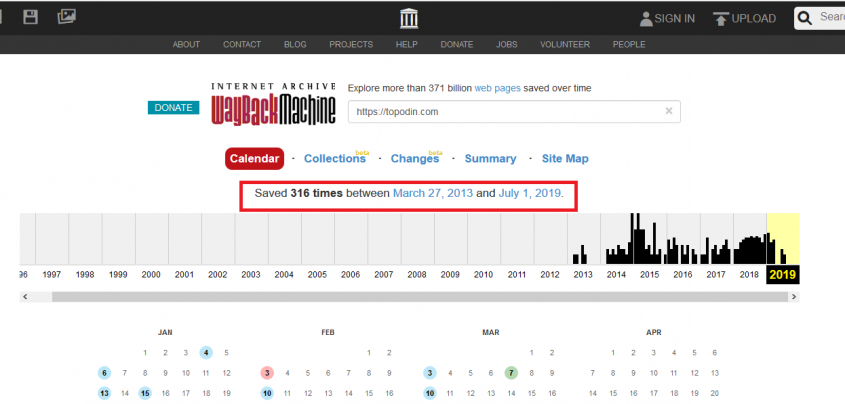
В интерфейсе приложения есть несколько вкладок, кликая по каждой из них, исследователь получает информацию одного русла. Подробнее об этом далее.
Закладки, по которым доступны исследования
На начало июля 2019 в сервисе Wayback Machine имеется 5 активных вкладок:
- Calendar (Календарь)
- Collectionsbeta (Коллекции глобальных проектов сети, как-то Википедия или ТвиттерTwitter (твиттер) — наиболее известный в мире микроблог, созданный для общения посредством коротких заметок. Здесь можно найти новых друзей, здесь можно раскрутить…Перейти к словарю терминов )
- Chagesbeta(Изменения представлены на «тепловой» диаграмме)
- Summary (Общие данные о проекте – особенно полезны при анализе конкурентов)
- Site Map (КартаSitemap - карта сайта - файл в формате XML и/или HTML с информацией о всех веб-страницах ресурса, которые нужно проиндексировать. Используется…Перейти к словарю терминов Сайта и изменения в ней)
Кратко по каждому пункту.
Календарь
С помощью этой закладки определяют, как менялся сайт по дате и времени на протяжении всего времени своего существования. Если протестировать Topodin, легко увидеть, что в 2013 году проект продавал видеорегистраторы, аппаратуру для слежения, прочее специфическое оборудование. Уже в 2014 компания кардинально сменила направление деятельности на предоставление услуг по созданию, продвижению и сопровождению интернет-проектов. Кроме того, Топодин активно поддерживает организации и публичные личности, защищая их имиджа и повышая репутацию в сети.
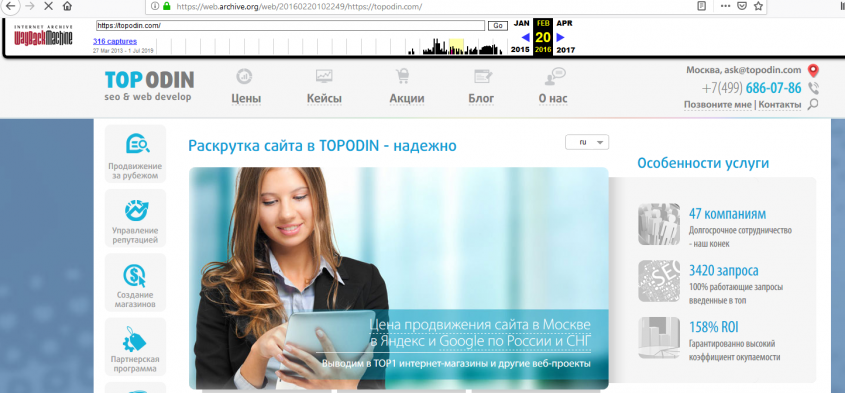
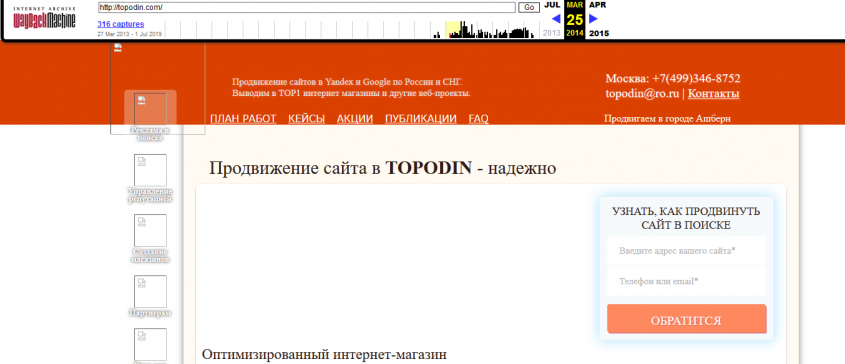
В открытом доступе имеются snapshot проектов на момент внесения каждого исправления. Стоит обратить внимание, что сохранения происходят даже в тех случаях, когда время между двумя ближайшими изменениями меньше минуты. Это стимулирует оптимизаторов собственных ресурсов работать точнее.
На втором скриншоте видны кружочки разного цвета, различия в выделении объясняются так:
- красные – это ошибки архиватора Машины Времени Сайтов;
- зеленые – данные, касающиеся редиректов проекта;
- голубые – исходная информация об изменениях записей в точное время и дату.
Кружочки в слайдере активные. Если навести курсор и нажать на время (а не просто дату) изменения, откроется внешний вид проекта к указанному моменту.
Коллекции глобальных проектов сети
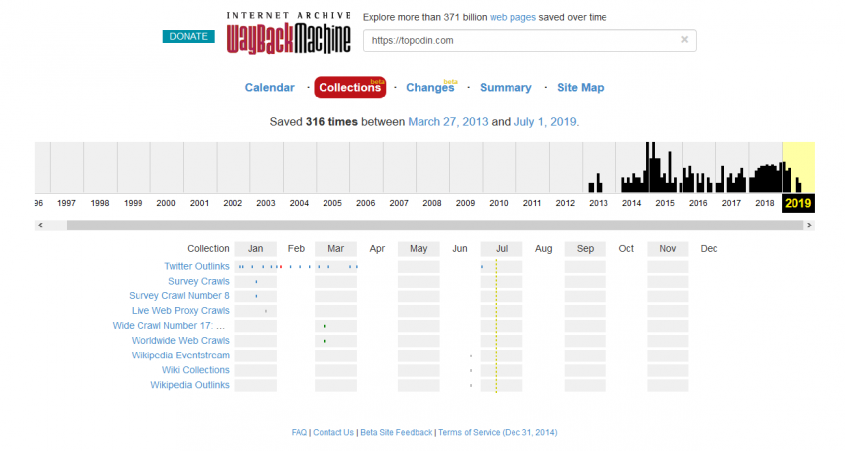
Collectionsbeta находится в стадии тестирования. Пока не удалось найти хоть какие-то комментарии относительно использования этой вкладки. Поэтому сначала просто суть. Всевозможные сайты такие, как Википедия, Твиттер, Live Web Proxy Crawls и другие периодически цитируют информацию из сети, дают ссылки на конкретные страницы. Закладка Collections, попросту говоря, показывает уровень цитируемости проекта на гипер трастовых площадках.
Так, Топодин в июне трижды упоминался на страницах разных сервисов Википедии.
Chagesbeta – еще одно тестируемое приложение
Календарь дает возможность увидеть случившиеся изменения на тот момент времени, когда они случились. Тогда как тестируемая вкладка Изменения, позволяет сравнивать запись проекта до фиксируемой отметки времени и после нее. Вот, что сказал о новом обновлении SEO консультант Сайрус Шепард:
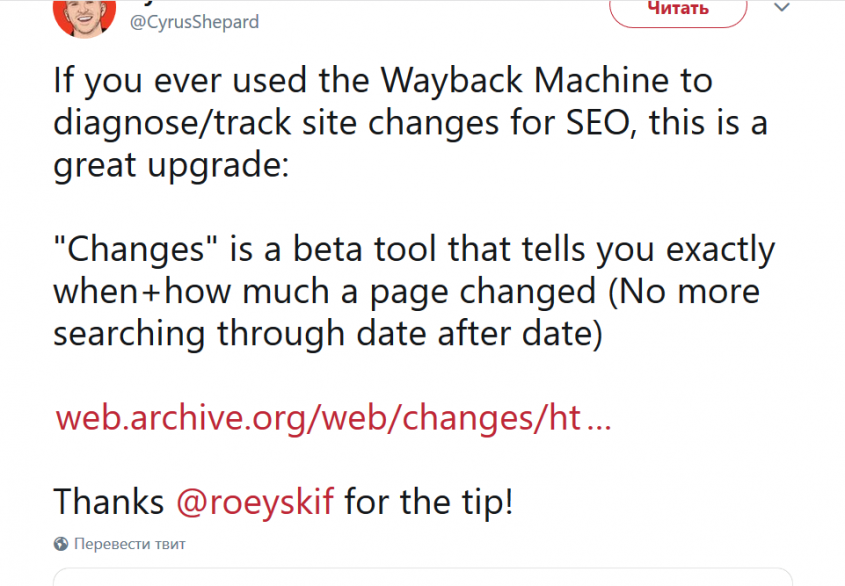
Суть его высказывания сводится к тому, что нового приложения достаточно для понимания сроков и объемов вносимых изменений. Больше этого даже искать нечего.
От редакции. Приложение новое, перспективное, но пока работает не всегда корректно.
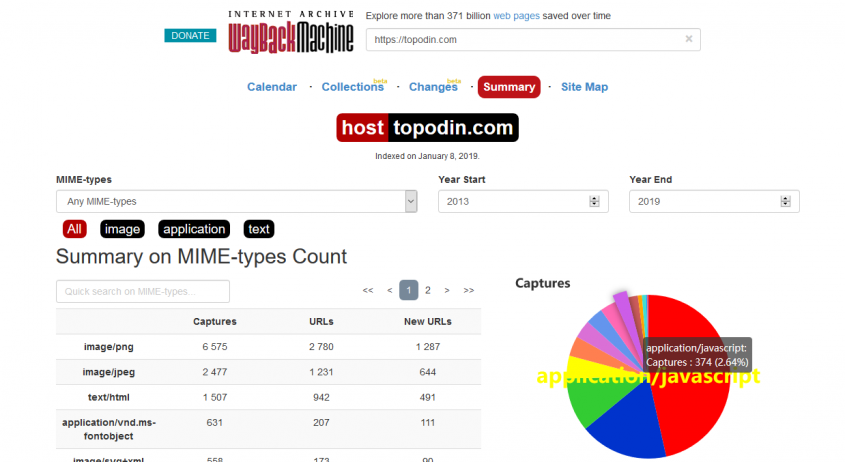
Summary
Общие данные о проекте собраны согласно того, какие у них расширения. Подсчитано число изменений, относящихся к разным видам изображений, таблицы стилей, скриптов, прочих элементов. Круговая диаграмма красноречиво говорит о соотношении количества обновлений в разных областях сайта. Их можно увидеть, в общей таблице или отдельно по каждому пункту:
- картинки;
- скрипты;
- тексты.
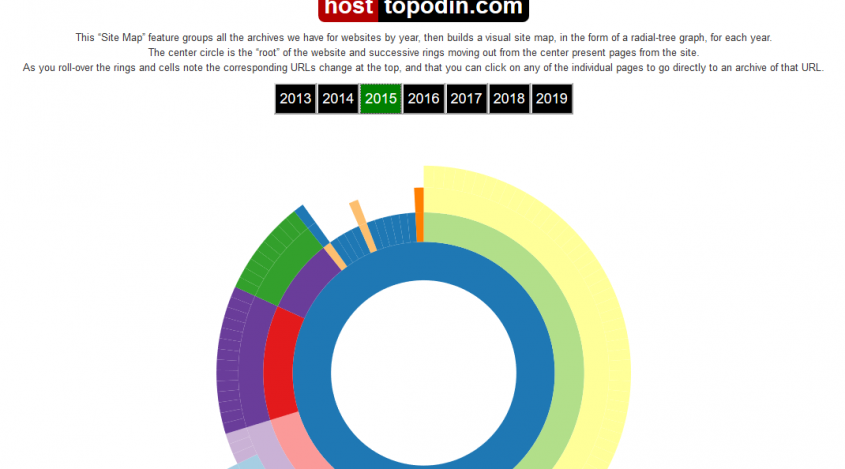
SiteMap – знакомство с картой сайта
По этой вкладке пользователи находят адреса, по которым происходили изменения в конкретную дату. Чтобы узнать такие данные, надо выбрать интересующий год, далее навести курсор на любую из зон диаграммы. Появится URL, где произошли изменения. Размер зоны говорит о значимости произошедших обновлений.
Что не вошло в описание закладок?
Если в Календаре выбрать назначенный день и час, кликнуть по активной ссылке, совершится переход на измененный в тот момент документ (страницу сайта). Но понять, что же именно изменилось, бывает не всегда просто. В помощь исследователям создана кнопка «Узнать об этой особенности». При нажатии открывается развернутый отчет: добавление или смена фото, обновление стилей, скриптов, прочего.
Практическое применение Wayback Machine
Некоторые примеры использования сервиса уже приведены ранее. Коротко о них:
- Определение изменений сайта (в том числе переход к работе в иной нише рынка).
- Проведение аудита клиентских проектов или анализа сайтов конкурентов.
- Работа со старыми редиректами и структурой бывших URL, зная приблизительную дату изменений, находят нужную информацию.
- Извлечение старого контента.
Теперь о тех возможностях, о которых еще ничего не было сказано. Это исследование файла robotПоисковый робот (бот, веб-паук, краулер) - программное обеспечение, часть поисковой машины, используемая для перебора веб-страниц для их занесения (вместе с…Перейти к словарю терминов .txt. Это дает возможность увидеть старую версию и определить следующие проблемы:
- внесенные изменения в структуру проекта во время хакерских атак, если таковые случались;
- технические проблемы сайта, приведшие к его «обвалу»;
- неудачные обновления (скриптов, таблиц стилей, картинок, кнопок, прочего);
- действительные причины уязвимостей.
С помощью данных из веб-архива проводят сверку с результатами аналитических систем. По старому скану страницы определяют правильность показаний счетчиков.
Менее очевидные способы использования
Wayback Machine применяют для аналитических исследований. Измерение пути пользователя, имея текущие и предшествующие данные, сравнивают и выбирают лучшее. Например, в какой-то период времени произошел резкий рост конверсии. Сервис поможет понять, по какому пути шел пользователь к покупкам. Оптимизаторы, работающие с данными от Машины Времени Сайтов, точно знают об актуальной эффективности каждого элемента страницы: кнопки, ссылки, эмодзи или чего-то еще.
Допустим, к вам пришел клиент, сайт которого имеет неудачную структуру. Надо удостовериться, что представленная версия – первая. Иначе надо изучить все предшествующие интерпретации проекта, чтобы не вернуться к прошлым ошибкам проекта. С помощь описываемого сервиса оптимизаторы получают представление о текущей и всех прошлых структурах сайта:
- объединение категорий;
- добавление новых разделов проекта;
- наоборот, разделение категорий, удаление не нужных.
Важно, что специалисты могут опираться на опытные результаты, уже бывших ранее изменений (избегают ошибок предшественников).
Следующий шаг – проведение анализа трафика посадочных страниц. С помощью извлечения старых версий проекта, а также расшифровки к ней, определяют наиболее эффективные landingLanding Page (в переводе с английского - "посадочная страница") - рекламная веб-страница, которая содержит данные о предлагаемой услуге или товаре. Обычно именно…Перейти к словарю терминов page и ключевые слова, по которым они продвигались. Эта возможность полезна маркетологам и потенциальным покупателям проекта. Всегда есть актуальные сведения о конверсиях сайта. Получить их можно по той самой кнопке «Узнать об этой особенности».
Восстановление сайта из веб-архива
Существует две принципиально разные ситуации:
- надо восстановить одну из старых версий проект;
- требуется получить данные о сайте до момента его падения (т.к. по каким-то причинам нет доступа к бэкап).
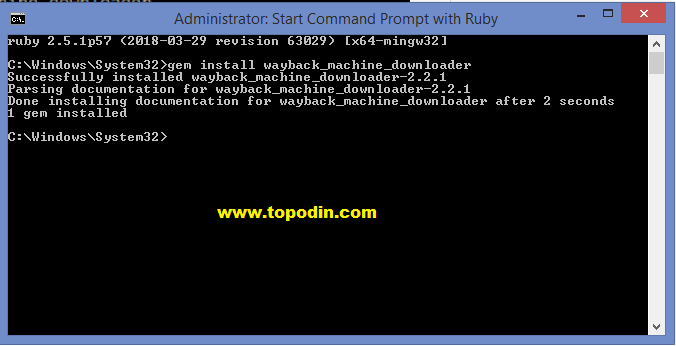
Но получить данные просто так не получится. В первом случае потребуется установка дополнительного ПО. «Руби» - это сервис, который поможет автоматизировать процесс скачивания. Приложение легко интегрируется с ПО Wayback Machine. Для начала работы необходимо установить Руби (apt-get install ruby). Далее добавить gem install wayback_machine_downloader. После чего станет возможным скачивание из веб-архива.
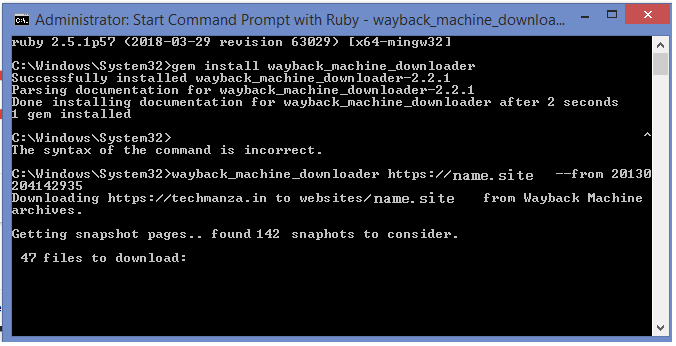
Желающие видеть, как продвигается процесс скачивания, могут указать отметку снапшота, ее получают из ранее описанных вкладок. Когда задается команда подсчета скачиваемых страниц, зная метку снапшота, программа сама определит число файлов и покажет на экране. После каждой командной строки с описанием скачиваемой страницы, картинки стоит номер очередности 11/142 или 27/142, остальные по аналогии.
Перед скачиванием необходимо лишь определиться с папкой, куда файл сохраняется, например: rsync -avh./websites/www.site.name/ /var/www/site.name/
Последний шаг – создание конфигурации в nginx, ожидание обновлений dns.
Восстановить сайт без бэкапа доступно при выполнении нескольких условий:
- Файл robot.txt не содержит запрещающих записей для краулеров Wayback Machine.
- Пользователь умеет заменять внутренние ссылки сайта на те, что создает сервис, например, такие: https://web.archive.org/web/20190310045353/https://topodin.com/.
- Наличие данных о проекте в каталоге DMOZНынче закрыт насовсем. DMOZ - многоязычный открытый каталог веб-ресурсов международного уровня, предусматривающий ручную модерацию. Название представляет…Перейти к словарю терминов , альтернативно, используют ссылки из трастовых источников (Гугл, Твиттер, прочих).
Поскольку подобные работы на сайте могут привести к грубым ошибкам, мы не станем углубляться в технический процесс. Главное, что надо знать нашим читателям – это следующий факт. Если данные о проекте по каким-то причинам утеряны, вариант восстановления через приложение Wayback Machine – пусть долгий, но все-таки надежный способ вернуть утерянную версию.
Использование сервиса для поиска уникального контента
Ежедневно сотни сайтов прекращают существовать в свободном доступе: закрываются, блокируются, удаляются владельцами. Но все данные, которые они содержали, сохраняются в рамках веб-архива. Если кому-то жжет, сказать: интернет – это мусорка, самое время осуществить желаемое. Но плюс в том, что среди всего невостребованного хлама встречается уникальный и даже полезный контент. Машина Времени сайтов хранит текстовые, аудио, видео файлы, поиск которых можно подчинить нескольким алгоритмам.
Поиск полезных статей организуют по следующей схеме:
- На сайте Reg.ru скачать перечень ресурсов, недавно прекративших существование (тематика задается индивидуально).
- Чтобы найти сохраненные копии, используют сетевой архив.
- Получив доступ к сайту, проверяют тексты на уникальность.
- Если материал еще не использовали конкуренты, смело публикуйте подошедшие статьи.
Не владельцы сайтов довольны подобным положением дел. Поэтому обычно, чтобы запретить доступ сервису к данным проекта, в электронной библиотеке прописывают следующую директиву внутри robots.txtRobots.txt (в русскоязычной транслитерации - "роботс") - файл, позволяющий регулировать индексацию веб-ресурса ведущими поисковиками. Этот текстовый документ…Перейти к словарю терминов :

Качество заархивированных сайтов: почему наблюдается большая разница?
Изучающие коллекции на Wayback Machine, десятками или сотнями файлов, невольно наталкиваются на объекты, которые называют «битыми» (не работающими). Часть из них – пустышка, остальные имеют плохое или вовсе ужасное качество. Некоторые проблемы с записью можно увидеть и на изображениях выше, где рассказывалось о краткой истории сайта Топодин. Файл с ранней датой записи не отвечает высокому качеству.
Вот какие причины несовершенства в работе сервиса называют его разработчики:
- Существует вероятность, что документ robots.txt приостановил запись. Тогда пользователь видит результат сканирования лишь для части страницы.
- Использование элементов Javascript снижает качество архивации. Особенно, когда происходит генерация ссылок посредством скриптов без полного названия посадочной страницы.
- Еще одна ситуация с javascript. Иногда требуется соединение с исходным сервером, тогда архивация невозможна.
- Аналогично для остальных функций проекта (карты изображений). Потребность связаться с первоначальным сервером останавливает архивацию.
- Когда на сайт нет совсем ссылок, краулер Wayback Machine не «встретит» проект и не сохранит его страницы.
Судебные разбирательства
Некоторые пользователи интересуются доступом к страницам Wayback Machine с демонстрации архивов в судебных институтах. Не стоит заблуждаться и рассчитывать на слишком многое. Разработчики архива заверяют, что сервис не предназначен для легального использования.
Однако в истории существования компания был, как минимум, один прецедент, когда администрацию пытались привлечь к ответственности в суде. Но суть инцидент лежала несколько в стороне от зоны влияния самой Wayback Machine.
Это случилось еще в 2009 году. Рассматривалось дело Netbula, LLC против Chordiant Software Inc. Компании были изначально связаны (на базе одного проекта открывался другой). Создатели Netbula решили использовать в тексте robot.txt запрет на доступ архивному краулеру к сканированию и сохранению страниц. Политикой Машины Времени Сайтов подобная ситуация предусмотрена. Для компании инициатора отказа действие с запретом означает, что все предшествующие версии проекта удаляются из истории веб-архива.
Решение Netbula затронуло интересы Chordiant. Последняя ходатайствовала в суде о вынесения решения – запретить Netbula ограничивать архивацию данных. В Chordiant посчитали, что в оставшихся копиях есть информация полезная для бизнеса. Суд вынес решение об удовлетворении интересов ходатайствующей стороны. При этом представители Wayback Machine выступали в суде, как свидетели и эксперты.
Еще несколько слов о сетевом архиваторе
Сервис работает бесплатно, выживая исключительно за счет дотаций, подобно Википедии и другим альтруистически настроенным проектам. Владельцы сайтов, которые ставят знак равенства между значимостью публикаций и их секретностью, могут воспользоваться запретом на архивирование через robot.txt. Но многие разработчики предупреждают, что на случай распространения глобального вируса или критического обвала, потеря доступа к услугам Машины Времени Сайтов может оказаться невосполнимой.
Актуальные в 2023 году альтернативы Машине времени сайтов
Если надо узнать возраст сайта, достать нужный удаленный контент или узнать, как выполняли продвижение конкуренты, то регистрация на Машине Времени сайтов - это не единственный способ. В 2023 году схожие возможности имеют и другие, в том числе бесплатные сервисы и программы. Вот несколько актуальных инструментов:
1.Archive.today. Это архивная платформа, которая среди прочего поддерживает JavaScript и Visual Basic. Сервис еще более впечатляет тем, что в нем работают две лучшие поисковые системы: google и yandex. Таким образом, если один поисковый гигант имеет какие-то технические проблемы, то другой сможет занять ее место — а значит, ни один архивный снимок или статья не останется без внимания!
2. Time Travel - бесплатная и удобная версия wayback machine в 2023 году, предоставляет людям метод просмотра версий сайта из прошлого.
3. У сервиса Visualping есть некоторые недостатки — невозможно вернуться в прошлое без дополнительных телодвижений. Сначала необходимо ввести url и выбрать интервал для сохранения происходящих изменений, а затем нужно указать адрес электронной почты, чтобы уведомления со снимками отправлялись прямо туда.
4. Cacheview предоставляет полезную услугу, архивируя веб-сайты из трех отдельных источников (coral, wayback machine и кэшКэш поисковика (в переводе с английского "тайник") - весь перечень данных, содержащихся в данный момент в поисковой системе. Информация, считанная,…Перейти к словарю терминов google). Наиболее примечательным аспектом этой услуги является то, что она предоставляет доступ к кэшу google.








